I Turned My Newsletters Into a Podcast. Here's What Broke.
A month of listening to a self-hosted newsletter-to-podcast pipeline, and what it revealed about TTS for journalism.

Money Stuff lands in my inbox five days a week and runs 3,000 words on a typical day. Ed Zitron writes 5,000-to-10,000-word posts on AI and tech-industry rot every week or so. Both are unusually good. Both pile up in my reading list and stay there, because sitting down to read for an hour at a stretch is not what my day looks like. Listening time is different: I have plenty of it during commutes, walks, and cooking, and I already listen to podcasts during all of them.
The obvious fix is something like Pocket’s text-to-speech feature, but the obvious fix has been bad for years: robotic narration, missing articles, no control over what gets queued. So I built my own.
The pipeline pulls newsletter emails from Gmail via IMAP, extracts article bodies with trafilatura and per-source cleanup rules, synthesises audio with Kokoro-82M on CPU, generates an RSS feed, and serves it with basic auth from a Hetzner box. Stack: Python with imap-tools, trafilatura, pydub, feedgen, mutagen, and SQLite for state. A systemd timer checks for new articles every 30 minutes. The feed shows up in my normal podcast app alongside everything else.
It works. I’ve been using it daily for a month.
This post isn’t about the tool. It’s about what a month of listening taught me about TTS for journalism: where the technology has quietly stopped being the bottleneck, and where the real audio-quality problems actually live. The code is public at github.com/tyler-martin-12/newsletter-podcast-public, but the repo is shared as a reference, not a product.
What I noticed
The first surprise was how good Kokoro is. The model is 82 million parameters, runs on CPU, and is free. I had braced for the kind of robotic narration that has made every previous attempt at this feel like homework. What I got was a default American female voice that handles ordinary prose with appropriate pacing, breath, and emphasis. Money Stuff in particular reads remarkably well: Levine’s long sentences, his nested parenthetical asides, his shifts between analysis and quoted source material, all delivered without the prosodic flatness I expected.
A specific example from a London Centric piece on charity fundraising:
Amid mounting concern from well-meaning donors, the Fundraising Regulator, which is run and funded by registered charities, has attempted to crack down on the growing number of these non-charitable organisations.
The middle clause is delivered with the pacing of a parenthetical, not flat-read as if the commas weren’t there. This is the kind of thing I would have predicted Kokoro would fail at. It doesn’t.
The second surprise was that the failures, when they came, were almost never about lexical accuracy. Kokoro very rarely gets a word wrong. What it gets wrong is structure, context, and convention.
The four failure modes I noticed most often:
Structural blindness. Kokoro reads text. It does not read structure. Section headings flow into the following paragraph as if they were the first sentence. Lists of headlines run together as one breath. Block quotes are indistinguishable from the narrator’s voice. Carbon Brief’s Daily Briefing is the canonical case: it’s literally a list of separate stories with their own headlines, and the audio renders it as one continuous paragraph.
Speaker non-differentiation. Platformer’s interview format is “Newton: X. Levie: Y.” On the page this is fine. In audio, both speakers come out in the same voice with no tonal shift, and by the third exchange I had genuinely lost track of who was saying what. This is catastrophic for any interview-heavy publication.
Domain-context failures on units and initialisms. A human reader, narrating an article about Chinese energy production, says “gigawatts” when the text reads “GW.” Kokoro says “G W.” In a vehicle context, the opposite problem shows up: “EV” should be read as “E V,” but Kokoro reads it as “eve,” as in Adam and Eve. These are technically close in the narrow sense: the letters are on the page. But a human newsreader would use context to choose the spoken form, and the result of not doing so is that energy and tech articles feel like they’re being read by someone who doesn’t understand them.
Homograph errors. “Row” in a London Centric piece about a public dispute is rhymed with “bow,” as in the front of a boat, when context unambiguously demands “row” rhyming with “wow.” Same word, two pronunciations, and the model does not reliably use the sentence-level context needed to choose the right pronunciation.
There are smaller things too. Kokoro reads “April 2” as “April second” sometimes and “April two” other times, with no apparent rule. Ellipses get sped through rather than paused over. None of these are deal-breakers individually. Cumulatively they’re noticeable.
What’s notable about all of these is what they have in common. The words are right. The audio is intelligible. What’s missing is the second-order information a human reader brings: that a heading is a heading, that two speakers are two speakers, that GW means gigawatts in this context, that this particular “row” is an argument and not a boat. The TTS model has solved the first-order problem, saying the words, and has no purchase on the second-order one, saying them with appropriate context.
This distinction turns out to matter when you try to measure quality.
A straightforward eval
I built a Whisper-WER eval, partly because that’s what TTS evaluation usually looks like and partly to see what such an eval would actually catch.
The setup: 15 articles, 3 each from Bloomberg, the Guardian, MIT Technology Review, The Atlantic, and WIRED. Roughly 66 minutes of audio. Each Kokoro-generated excerpt was transcribed with faster-whisper, aligned against a windowed slice of the cleaned source text, and compared with standard WER. The cleaned source is the exact string that was fed to Kokoro, so the reference and the audio are tied to the same input.
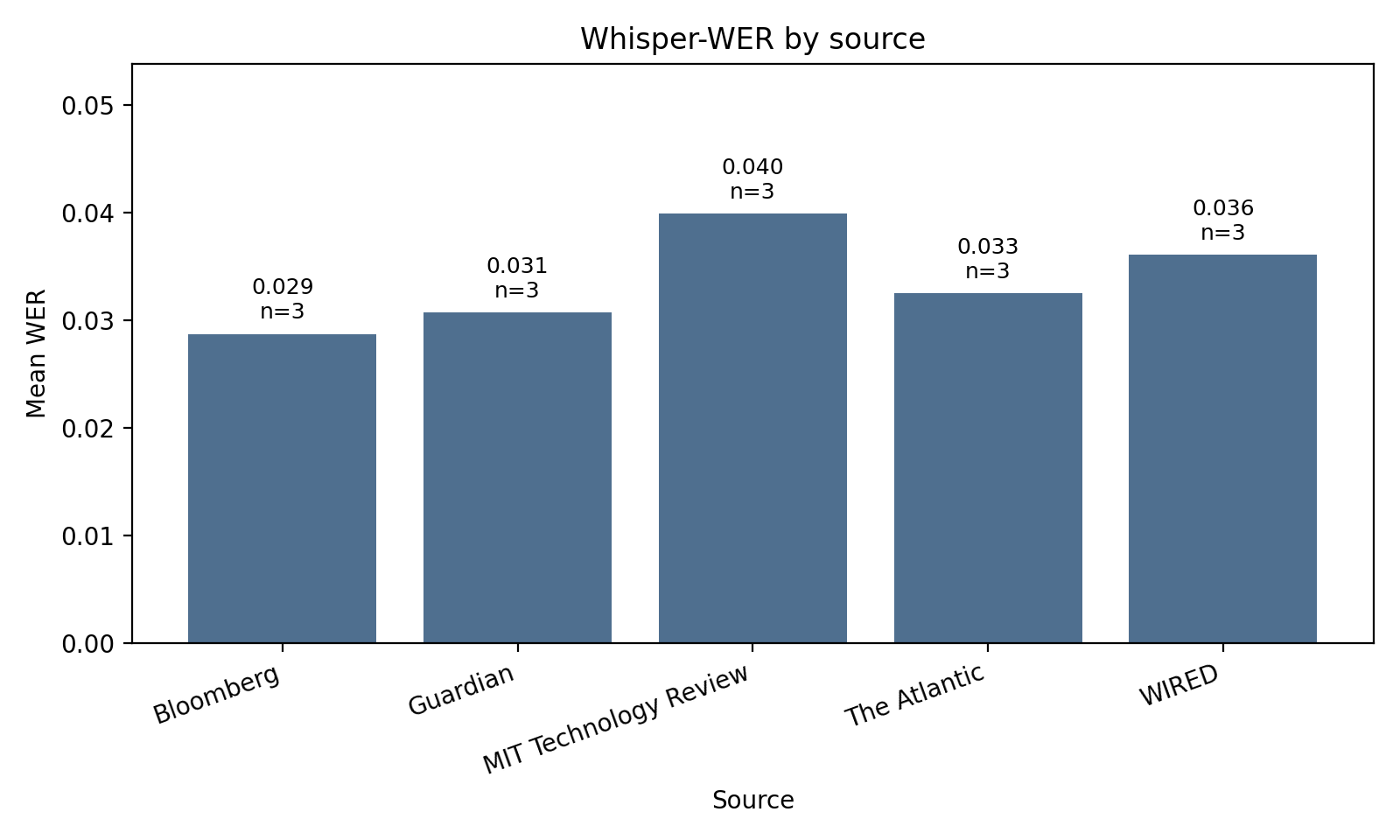
The headline result: across 66 minutes of audio, manual inspection of the surfaced errors found one meaning-relevant lexical error. The word “target’s” came out as “target” in Money Stuff: Not Merging Is Not Securities Fraud, around the 7-second mark. Everything else WER flagged was one of:
- Proper nouns Whisper itself struggled with: Tarique, Agrawal, Haarnoja, the brand name UnHerd.
- Tokenisation artefacts: ChatGPT split as “chat G P T” by Kokoro and transcribed that way.
- Acronym expansions that disagreed with the source text not because Kokoro got them wrong but because the reference had “AI” and Kokoro correctly said “AI” while Whisper inconsistently transcribed it.
- Punctuation and contraction differences invisible to a listener.
Mean WER across the sample was 0.034, or 0.033 weighted by duration. That sounds low, and it is. The implication that should be carrying real weight here is this: for an 82-million-parameter open-weights model running on CPU, lexical accuracy on long-form journalism prose is no longer the bottleneck.
But: none of the failure modes from the previous section appear in this number, and most of them weren’t the kind of thing WER measures in the first place. The Platformer interview collision, where two speakers blur into one, is invisible to WER. Both voices say the right words. The Carbon Brief headline run-on is invisible: every word is correctly pronounced, only the pacing is wrong. The “G W” reading is one WER substitution per occurrence, which radically understates its effect on whether the article feels like it’s being read by someone who knows what they’re talking about. The “row” homograph is one substitution if Whisper bothers to flag it at all, and zero if Whisper transcribes the audio as “row” without specifying pronunciation.
WER measures what TTS used to fail at. Modern small TTS models don’t fail at that any more. The metric and the problem have separated.
Extensions I tried
The obvious next move was to add an LLM preprocessing layer that would expand initialisms, normalise dates, and fix the comprehension-level issues that the eval was flagging. The hypothesis was straightforward: pass the cleaned text through Claude before sending it to Kokoro, ask the model to rewrite the text as a human reader would speak it, and watch WER go down.
I tested two variants. The first was whole-text rewriting: feed the article in, get a rewritten article out, run it through Kokoro. The second was targeted span replacement: ask the LLM to return only a list of specific substitutions, with surrounding context to disambiguate, and apply them mechanically.
Whole-text rewriting made WER worse on two of three pilot articles. The reason was that Claude over-edits. Given an article and a licence to rewrite it for speech, it expands contractions, restructures punctuation, changes quote styles, and occasionally paraphrases. Some of these changes are reasonable for a human narrator. None of them help WER, and several of them hurt it by introducing new tokens that Whisper then has to match.
Targeted span replacement avoided the regression. It also produced near-zero WER change on the pilot sample. The reason was that the three pilot articles, Bloomberg, MIT Technology Review, and The Atlantic, were prose-heavy and had very few unit or initialism instances for the targeted normaliser to fix. The one substitution that did apply, “CO2” expanded to “carbon dioxide” in a Bloomberg piece, fell outside the audio window that was being evaluated.
I tried per-source profiles too, on the theory that London Centric might benefit from British pronunciation hints and Carbon Brief from unit expansion rules. At this sample size, profiles were unstable: two of three articles got worse under profiling, MIT Technology Review dramatically so. Three articles per source isn’t enough to learn a stable profile against. Shelved.
The honest conclusion from all of this is one I didn’t expect when I started: Kokoro’s built-in text frontend is already doing most of the work an LLM normaliser would do. Aggressive preprocessing is harmful. Targeted preprocessing is at best modestly useful, and only on the kind of unit-heavy text my sample didn’t well represent.
The deeper point follows from the section above. The audible problems from a month of listening are not preprocessing problems. Heading-as-prose can’t be fixed by rewriting the words: it needs the TTS layer to know “this is a heading” and treat it differently. Speaker non-differentiation can’t be fixed in text: it needs voice switching at synthesis time. Homographs need phoneme-level control that prose-trained open-weights TTS models don’t currently expose.
If you’re building audio for a publication, the lesson is: invest in the text-structure layer, not the text-normalisation layer. The normalisation problem is mostly solved. The structure problem isn’t.
What I’d build next
A few candidates, ordered by how much they’d improve the listening experience:
Heading and structure markup at the extraction layer. trafilatura already extracts document structure. The question is whether you can pass that structure through to Kokoro via inline markers, or whether you need to render heading audio in a different voice, or with explicit pauses, and concatenate at the audio level. Probably the highest-leverage fix and the one I’d attempt first.
Voice switching for quoted dialogue. Kokoro ships with several voices. Detecting attributed dialogue at extraction time, “‘X,’ Newton said”, and routing those segments to a second voice would fix the Platformer problem entirely. The detection is the hard part: pulling “X said” out of prose is straightforward; pulling out the speaker-turn structure of a Q&A format is harder.
Per-publication default voices. Listening to a London paper in an American female voice is mildly comical. Kokoro has British voices. Carbon Brief in a more measured scientific-podcast voice. The Atlantic in something with more literary weight. Cosmetic, but real.
The broader implication, if there is one: TTS for journalism has crossed a threshold. The model is no longer the bottleneck. The bottleneck is the pipeline around the model, and that pipeline is where the interesting product work is now.